
Hey everyone! Today, I’m excited to share my experience in building an automated pipeline for processing NCAA game highlights. This project involved a blend of different technologies: a Python application, Docker for containerization, AWS S3 for storage, and AWS MediaConvert for video processing. It was a challenging but rewarding experience, and I'm excited to walk you through the entire process, including the hurdles I faced and the solutions I found.
Project Overview
My goal was to create a system that could automatically retrieve NCAA game highlights from a third-party API, store the raw video in S3, and use AWS MediaConvert to process the video for better playback across devices. I wanted a hands-off approach, where I can simply kick off the pipeline and it would retrieve, store and process the video.
Key Technologies Used:
- Python: For the core logic of the application.
- Docker: For containerizing the application and its dependencies.
- AWS S3: For storing raw and processed video files, along with the JSON metadata.
- AWS MediaConvert: For converting the videos to a standardized format.
- RapidAPI: To retrieve game highlights from the Sport Highlights API.
- Environment Variables: Used for flexible configuration
- Retry Logic: implemented for robustness
Project Structure
The project was structured logically into a few key files and folders:
src/
├── Dockerfile # Defines how to build the container image
├── config.py # Manages all of the environment variables
├── fetch.py # Fetches highlights from the API and saves the JSON response in S3
├── mediaconvert_process.py # Processes a video file using MediaConvert
├── process_one_video.py # Extracts video URLs, downloads and saves the video file in S3
├── requirements.txt # Python dependencies
├── run_all.py # Executes the python scripts in the correct order
├── .env # Stores all environment variables
├── .gitignore
└── terraform/ # Terraform scripts
├── main.tf
├── variables.tf
├── secrets.tf
├── iam.tf
├── ecr.tf
├── ecs.tf
├── s3.tf
├── container_definitions.tpl
└── outputs.tf
Implementation Steps
- Setting up RapidAPI: First, I created a RapidAPI account and subscribed to the Sports Highlights API. This API would serve as my data source for fetching NCAA game highlights. I had to create the API key and save that for the next steps.
- Creating the Python Scripts:
- `config.py`: I started by defining my environment variables and using the `os` library to access these variables to ensure I can easily customize the settings for different environments or runs.
- `fetch.py`: This script is responsible for fetching data from the RapidAPI. I passed the necessary headers and parameters, and then downloaded the json response, before saving the response to an S3 bucket.
- `process_one_video.py`: Here, I built the logic to connect to the specified S3 bucket, download the json file, extract the video URL, and download and save the video to another S3 bucket folder.
- `mediaconvert_process.py`: This part of the script sets up and submits a MediaConvert job to transcode a video stored in S3.
- `run_all.py`: This acts as the main execution point. I used the subprocess library to execute my Python scripts in a specific sequence, along with delays between them to allow resources to stabilize. I also added retry logic for each script to improve fault tolerance.
- Containerizing with Docker: I created a `Dockerfile` to package my Python application and all its dependencies into a Docker image. I started with a `python:3.9-slim` base image, installed my requirements, copied my scripts and then defined an entrypoint to begin the execution.
- Storing Variables: I made use of a `.env` file to save all of my environment variables. I did this to follow best practices, where I shouldn't save sensitive keys in the source code itself. I used the `python-dotenv` library to retrieve the `.env` file.
- IAM Role and Policy: To allow the AWS resources to perform actions on my behalf, I created a custom IAM role.
- I used the following managed policies to attach to my role:
- `AmazonS3FullAccess`
- `MediaConvertFullAccess`
- `AmazonEC2ContainerRegistryFullAccess`
- I used the following trust policy, in the role:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "ec2.amazonaws.com", "ecs-tasks.amazonaws.com", "mediaconvert.amazonaws.com" ], "AWS": "arn:aws:iam::<\"your-account-id\">:user/<\"your-iam-user\">" }, "Action": "sts:AssumeRole" } ] }
- I used the following managed policies to attach to my role:
- Running Locally:
- I first built the docker image with `docker build -t highlight-processor .`
- Then I ran the container with `docker run --env-file .env highlight-processor`
Challenges Faced
This project was not without its obstacles. Here’s how I tackled some of the key challenges:
- S3 Bucket Creation Issues: Initially, I encountered issues with bucket creation. It turned out I was using a generic bucket name (`Highlight-Processor`). The fix was to ensure my bucket name followed the proper naming conventions. I also learned that if you already have the bucket, it will not try to create a bucket. So I had to create a new bucket, to have the code to create a bucket be tested.
- Access Denied/No Such Bucket Errors: I also got an access denied and No Such Bucket Error, which means that S3 could not connect to my resources or the bucket itself. This was due to a typo in the name of the S3 Bucket in the `.env` file. It is extremely important to verify your environment variables and ensure the resources you are trying to connect to is actually created and exists.
- `datetime` Serialization with MediaConvert: I got an error when creating my MediaConvert job, that said `Object of type datetime is not JSON serializable`. This was due to the way I was displaying the MediaConvert json object.
I fixed this by adding `default=str` in the `json.dumps` call.
# Print a success message indicating the job was created print("MediaConvert job created successfully:") # Convert the entire response to a string, handling potential datetime object print(json.dumps(response, indent=4, default=str)) - Docker Connection Issues: I also experienced a docker connection issue that required me to restart the docker app.
Overcoming the Challenges
The challenges provided valuable learning experiences. I learned the importance of:
- Double-Checking: I had to meticulously check the bucket name, region, and S3 configurations. It turns out even simple typos can cause frustrating errors.
- Understanding Error Messages: Carefully reading error messages pointed me in the correct direction, helped me isolate the issues and find the root cause.
- Incremental Development: Testing and verifying individual parts of the system rather than trying to debug everything at once.
- Seeking Help: I looked at forums, and chatgpt for possible solutions.
Successful Run
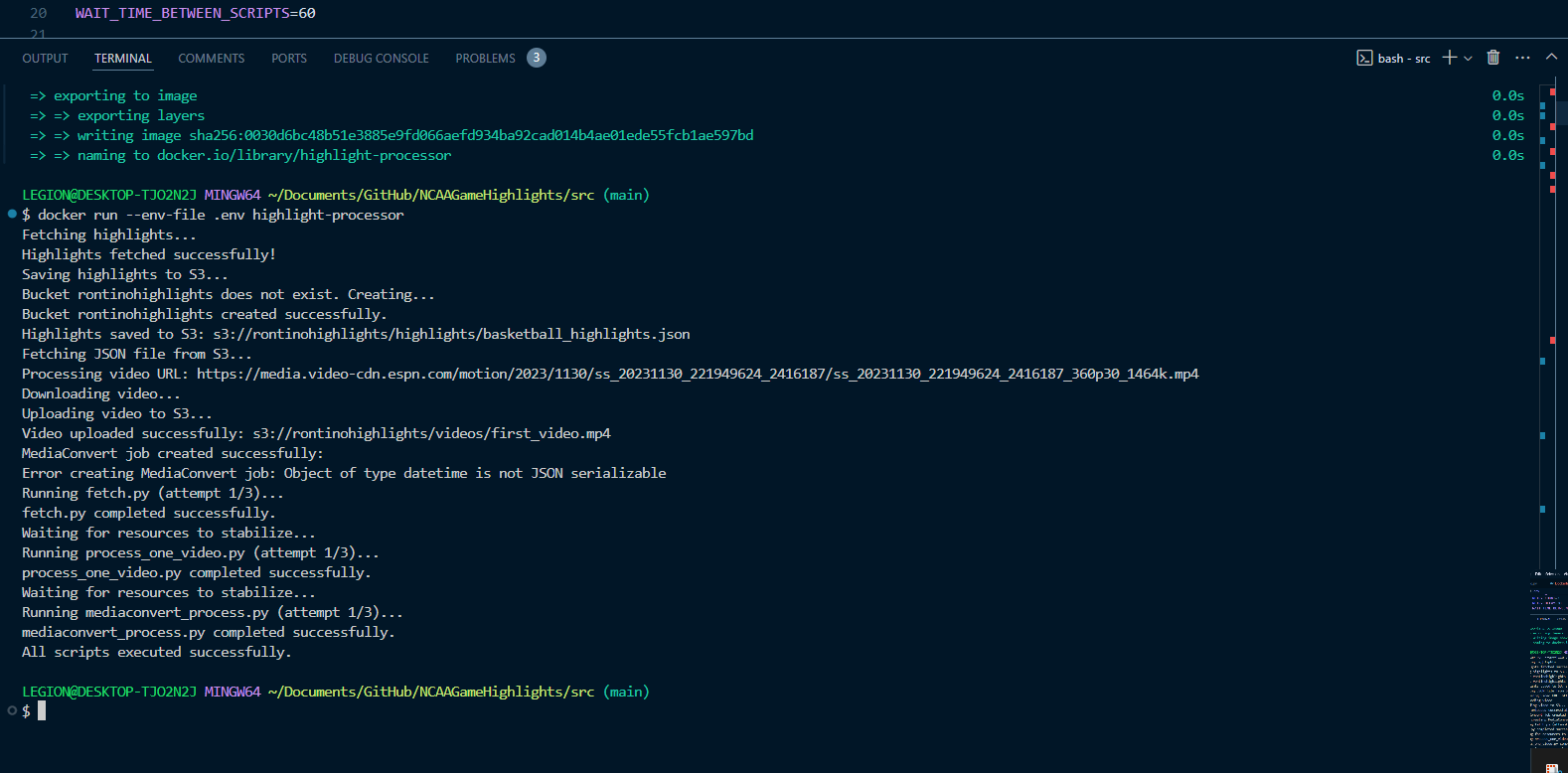
Finally, after fixing the S3 and MediaConvert issues, I got the entire system to work locally:
LEGION@DESKTOP-TJO2N2J MINGW64 ~/Documents/GitHub/NCAAGameHighlights/src (main)
$ docker run --env-file .env highlight-processor
Fetching highlights...
Highlights fetched successfully!
Saving highlights to S3...
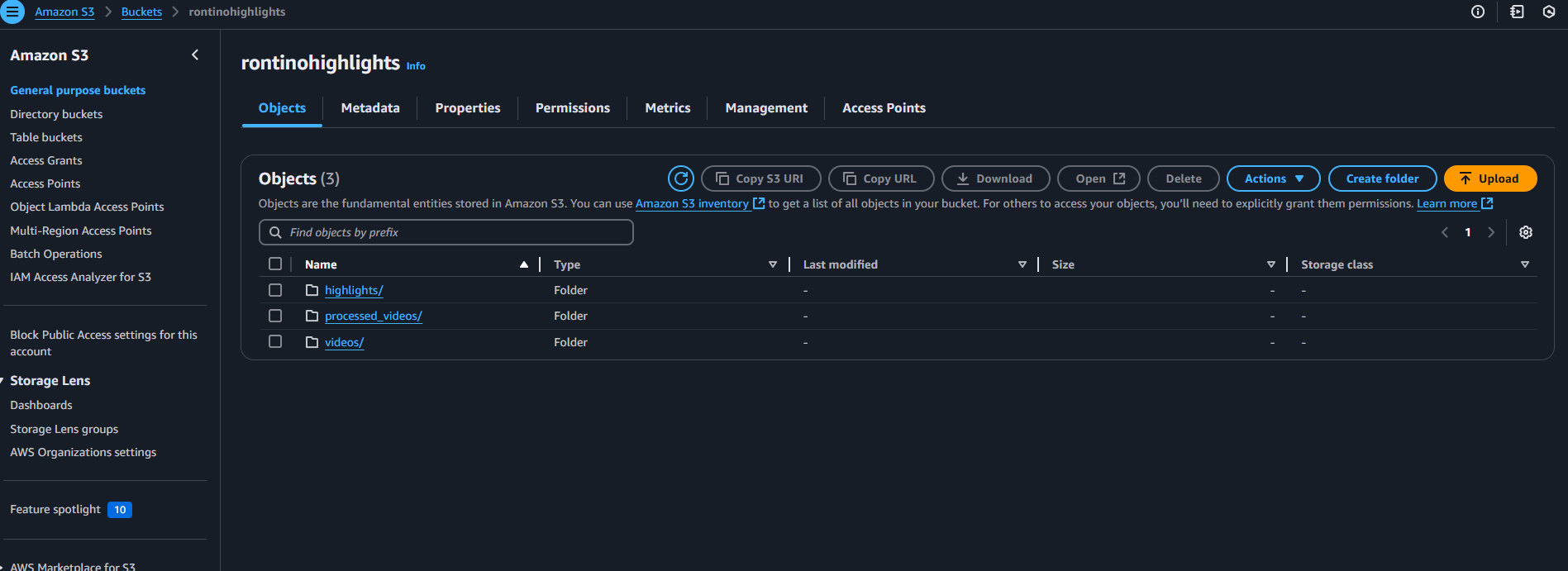
Bucket rontinohighlights does not exist. Creating...
Bucket rontinohighlights created successfully.
Highlights saved to S3: s3://rontinohighlights/highlights/basketball_highlights.json
Fetching JSON file from S3...
Processing video URL: https://media.video-cdn.espn.com/motion/2023/1130/ss_20231130_221949624_2416187/ss_20231130_221949624_2416187_360p30_1464k.mp4
Downloading video...
Uploading video to S3...
Video uploaded successfully: s3://rontinohighlights/videos/first_video.mp4
MediaConvert job created successfully:
Error creating MediaConvert job: Object of type datetime is not JSON serializable
Running fetch.py (attempt 1/3)...
fetch.py completed successfully.
Waiting for resources to stabilize...
Running process_one_video.py (attempt 1/3)...
process_one_video.py completed successfully.
Waiting for resources to stabilize...
Running mediaconvert_process.py (attempt 1/3)...
mediaconvert_process.py completed successfully.
All scripts executed successfully.
Conclusion
This project was a fantastic deep dive into building an automated media processing pipeline. I learned a great deal about integrating various AWS services, containerization with Docker, and the importance of robust error handling. It demonstrates the power of cloud services in handling complex tasks.
I'm excited to continue working on this project and add additional features in the future!
Future Enhancements
- Implementing the infrastructure as code with terraform
- Automating more than one video, and scheduling jobs
- Making the date dynamic, rather than static.
What are your thoughts? Please share any feedback !